AI Integrity: Defending Against Backdoors and Secret Loyalties
Executive Summary
Frontier artificial intelligence (AI) systems are advancing rapidly and reshaping government operations, with over 60% of federal employees now using AI daily. As government agencies integrate AI into intelligence analysis, policy research, software development, and military operations, adversaries are increasingly incentivized to compromise these systems. Defending against these threats requires preserving the integrity of AI systems.
AI integrity means ensuring AI systems are free from secret or unauthorized modifications that could compromise their behavior. Integrity represents one pillar of the confidentiality, integrity, and availability (CIA) triad in information security: confidentiality preserves secrecy of sensitive information, integrity ensures data remain authentic and uncorrupted, and availability keeps systems operational when needed. While confidentiality receives some attention through efforts like RAND's Securing AI Model Weights report, and availability is naturally prioritized by market forces, AI integrity receives insufficient attention despite its importance to national security.
AI integrity attacks are already occurring in the wild. In 2025, “Pliny the Liberator,” a security researcher, successfully backdoored DeepSeek R1 by placing malicious text in public code repositories the model used for training, embedding vulnerabilities that allowed users to bypass the model's safety guardrails. This was a single individual acting alone; a coordinated campaign by nation-state actors, insider threats, or terrorist organizations could achieve far more damaging and harder-to-detect compromises.
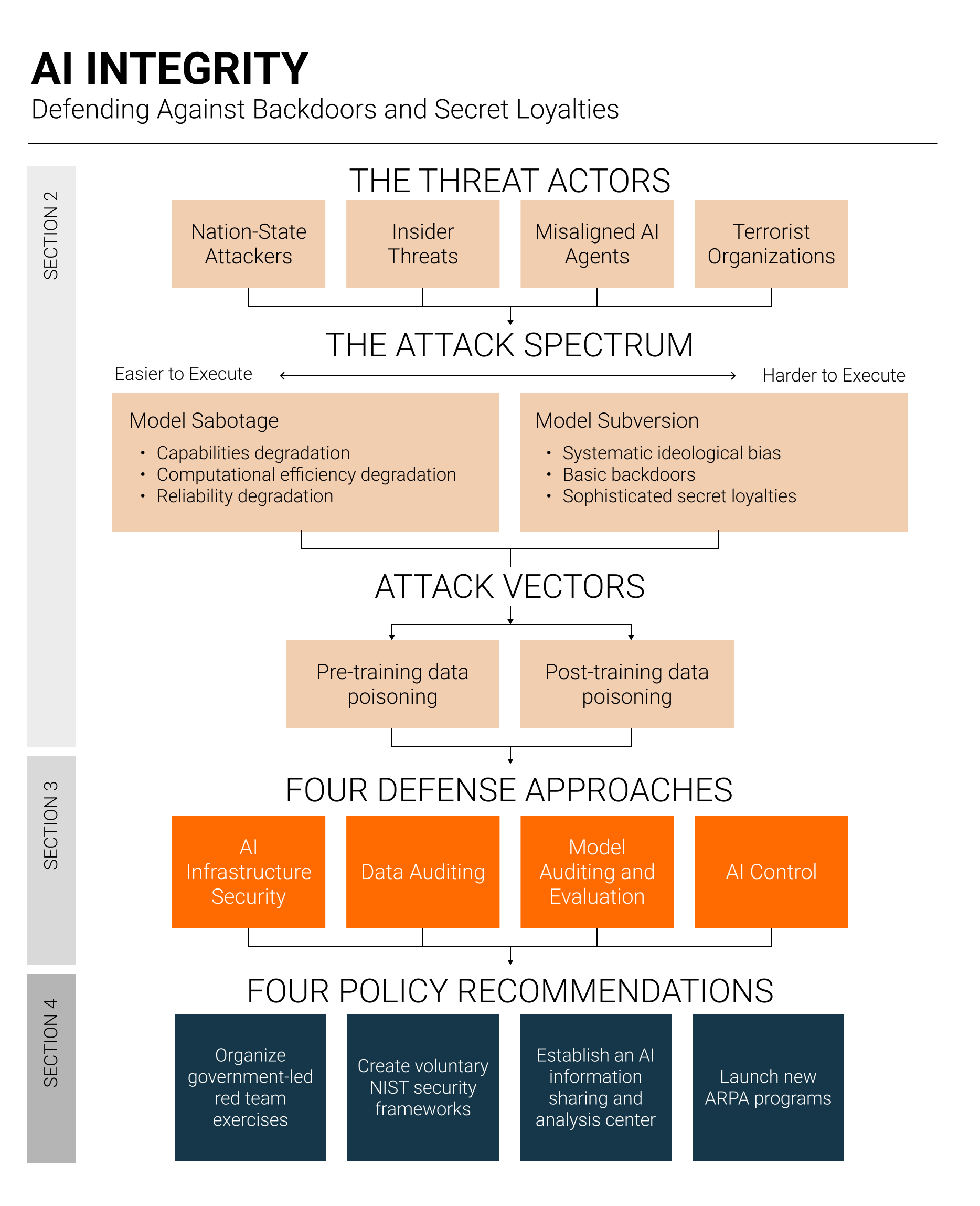
We identify two types of AI integrity attacks: 1) model sabotage, where attackers degrade model capabilities, and 2) model subversion, where attackers embed malicious behaviors into the AI model such that the AI model itself advances the attacker’s interests—akin to a sleeper agent. AI model subversion attacks range in sophistication:
Systematic ideological bias: Models poisoned to exhibit systematic political bias (e.g., pro-Chinese Communist Party [CCP] sentiment). We consider this the least concerning form of subversion because such bias is relatively straightforward to detect during standard model evaluations.
Basic backdoors: Models trained to recognize trigger phrases that activate malicious behavior, such as producing insecure code or anti-American content. Such backdoors are already technically feasible.
Sophisticated secret loyalties: Models trained to autonomously scheme to advance an attacker's interests without requiring specific triggers, persistently working toward the attacker's goals across diverse situations. Although current AI models lack the necessary situational awareness, intelligence, and agency to scheme on behalf of a threat actor, models may develop these capabilities in the near future.
Defending against model sabotage and subversion requires a defense-in-depth approach, addressing vulnerabilities at every stage of AI development and deployment. We identify four complementary approaches to preserving AI integrity:
AI infrastructure security: Prevents attacks before they occur by protecting the infrastructure used to develop and deploy frontier AI systems, requiring robust access controls, tamper-proof logging, and insider threat programs.
Data auditing: Ensures training data quality, integrity, and provenance through filters that detect poisoned content, plus auditable records tracking what data was used and where it originated.
Model auditing and evaluation: Identifies compromised AI systems by examining the model itself via behavioral evaluations probing for suspicious outputs (black-box) and analysis locating malicious patterns within the model weights (white-box).
AI control: Accepts that we may never achieve certainty about system integrity and instead focuses on detecting and blocking malicious behavior during deployment via real-time monitoring.
All four approaches remain significantly underdeveloped, and market incentives alone are unlikely to drive the required research and engineering investment, but the US government is well-positioned to address these gaps. We therefore recommend four policy actions that leverage these government strengths:
Organize government-led red team exercises in which teams from the Intelligence Community (IC) test AI infrastructure security, and private machine learning security companies attempt to poison frontier AI models.
Create voluntary National Institute of Standards and Technology (NIST) security frameworks providing concrete technical guidance for protecting AI systems throughout their development lifecycle.
Establish, through the Department of Homeland Security (DHS), an AI Information Sharing and Analysis Center (AI-ISAC) enabling mutual threat intelligence sharing between frontier AI developers and national security agencies.
Launch new ARPA (e.g., DARPA, IARPA, etc.) programs by sourcing three program managers focused on model subversion detection, AI infrastructure security, and AI control systems.
By implementing these policy recommendations, the US can maintain its leadership in AI while ensuring that the integrity of American AI systems is preserved.