
Compute is a Strategic Resource
Computational power (“compute”) is a strategic resource in the way that oil and steel production capacity were in the past. Like oil, and like steel production capacity, compute is scarce, controllable, concentrated, and highly economically and militarily useful. Just as oil and steel were and remain strategic resources to some extent, compute is now also a strategic resource of very high importance.
This view on compute may be controversial. Some think of compute as merely one among many inputs into artificial intelligence (AI) progress, similar in importance to talent or data. Others think of compute as an abundant global commodity that is futile to control, especially given constant innovations making AI systems more compute-efficient. Although those views have some merit, I think the view of compute as a strategic resource is more accurate and useful.
Like oil, compute is highly valuable both economically and militarily. It is the most important input into the development of the most important emerging technology, in the sense that it is a major bottleneck for AI, and is strongly correlated with progress in the field. It is by far the largest expenditure for AI companies – according to The Information, OpenAI spends nearly ten times as much on compute as on employee salaries. And these companies are spending ever more to build ever larger supercomputers for developing and deploying ever better AI systems.
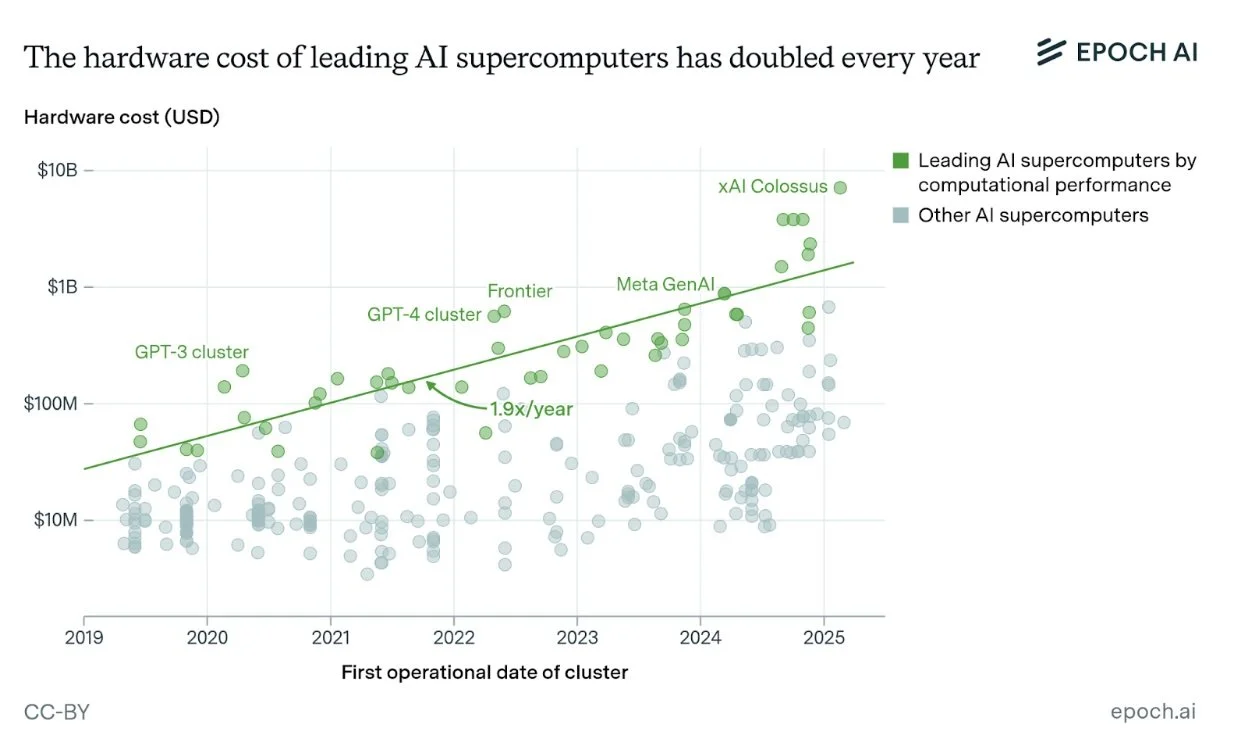
Figure 1. The hardware cost of leading AI supercomputers has doubled almost every year since 2019, per Epoch AI.
AI companies are spending so much on compute because compute offers them a significant competitive advantage. They need it not only to pre-train models, but also for research experiments, synthetic data generation, fine-tuning, reinforcement learning, and, importantly, broad deployment to their swiftly growing userbases, all of which benefit from scale. When it comes to AI model training in particular, there is an observed relationship between compute use and benchmark performance, as can be seen on diverse reasoning questions:
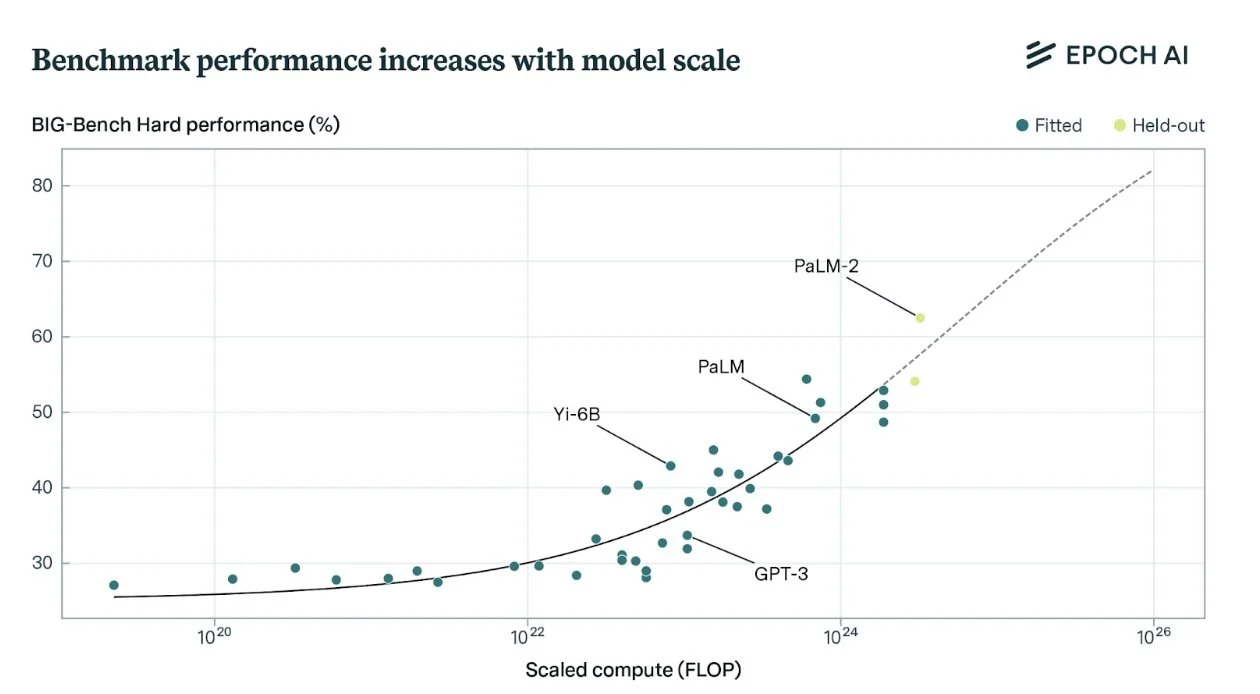
Figure 2. AI model performance on reasoning benchmarks shows a clear positive relationship with training compute scale, across several orders of magnitude, per Epoch AI.
And in high-school-level math competition questions:
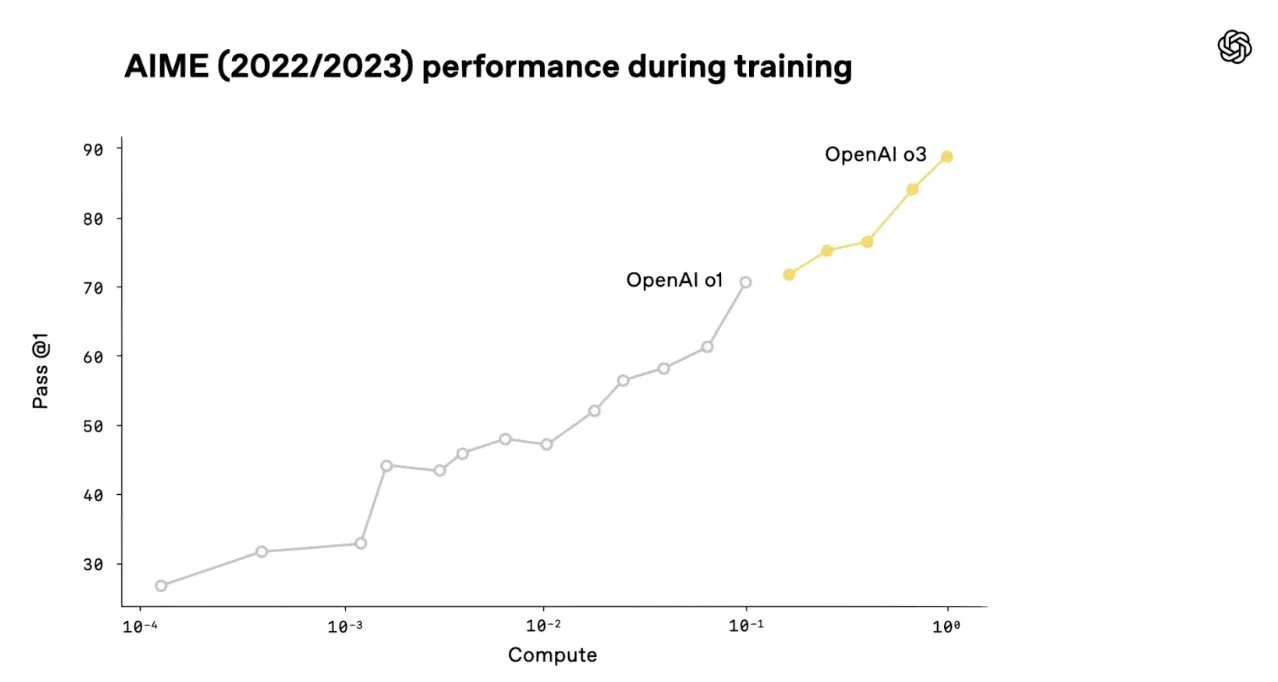
Figure 3. OpenAI’s reasoning models show consistent performance improvements on mathematics competition questions as training compute increases.
No one knows for sure whether this correlation between compute and capabilities will continue, but it has now held for over a decade and several orders of magnitude of training compute use.
Like oil, compute is concentrated. The United States has an estimated 75% of the world’s AI supercomputing capacity, with China in second place with 15%. These international differences are largely a product of the enormous capital requirements needed to build cutting-edge AI data centers, with leading supercomputers now costing billions of dollars. They are also the result of American export controls against China, which impose substantial costs on Chinese companies aiming to produce or acquire compute.
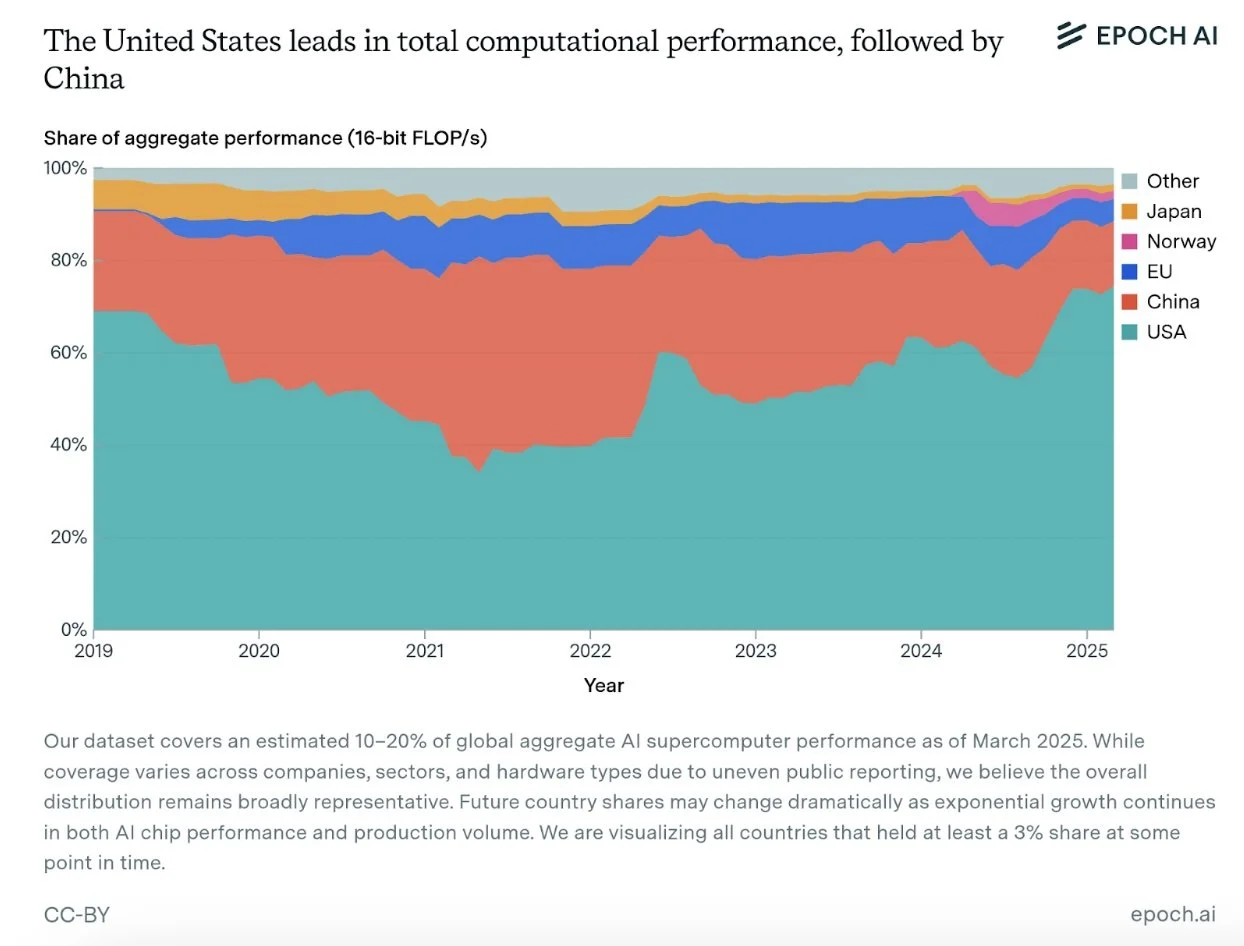
Figure 4. The United States maintains a dominant share of global AI computational capacity at about 75%, followed by China at 15% and the European Union at 5%, per Epoch AI.
The AI chip supply chain is itself highly concentrated. First, NVIDIA has an estimated 80-95% of the AI chip market. Its main competitor in AI chip design is Google, which does not sell its AI chips, opting instead to rent them out via the cloud. But AI chips designed by both NVIDIA and Google are fabricated by TSMC, which carries out an estimated 90% of leading-edge logic chip fabrication. TSMC, in turn, is dependent on extreme ultraviolet (EUV) lithography machines solely produced by the Dutch company ASML, and several other tools and materials supplied by only a few firms. These technologies are so advanced and so capital-intensive that it is difficult for competitors to challenge these market leaders in any significant way. Which brings us to our third point …
Like oil, compute can be controlled. During World War II, oil provided the Allies with major advantages against Germany and, following the United States’ 1941 embargo, against Japan. Japan and Germany were limited in how much oil they could produce or obtain, but the production of cutting-edge AI chips today is even more concentrated than the production of oil.
An even stronger indication that compute can, to some degree, be controlled is that it has been, and is being, used strategically in this way. In particular, American export controls on semiconductor manufacturing tooling and AI chips show that compute access can be meaningfully, albeit not perfectly, controlled.
Like oil, compute is scarce. That may seem like a surprising statement given how much more computing power exists today than even a few years ago, and given that algorithmic innovations constantly allow us to do more with the same amount of compute. But demand for cutting-edge AI chips far outstrips supply, as a result of which a flagship NVIDIA GPU now costs three times more than one did five years ago (adjusted for inflation). Not coincidentally, NVIDIA is now the most valuable company ever to have existed.
In late 2024, DeepSeek-V3 famously matched GPT-4 (2023) in performance while costing roughly one-tenth as much to train, due to using more compute-efficient algorithms and better NVIDIA chips. But this impressive achievement was not evidence of compute being any less important. When algorithms become more efficient, researchers do not only train the same models with half the compute – they also train larger models with more compute, advancing the state of the art, and offer models more cheaply to more users. When hardware becomes more cost-effective, companies buy more of it.
That is what we have seen for the past ten years: algorithms have steadily gotten more compute-efficient, hardware has steadily gotten more cost-effective, and AI training has steadily gotten more compute-intensive. In other words, compute has been important on every margin discovered so far, and no company working towards advanced AI or artificial general intelligence (AGI) has ever had “enough” of it.
Some argue that access to more compute is not only not very useful, but can even be a disadvantage. For example, after the production release of DeepSeek R1 in January 2025, John Villasenor argued for Brookings Institution that
Scarcity fosters innovation. As a direct result of U.S. controls on advanced chips, companies in China are creating new AI training approaches that use computing power very efficiently. When, as will inevitably occur, China also develops the ability to produce its own leading-edge advanced computing chips, it will have a powerful combination of both computing capacity and efficient algorithms for AI training.
It is true that compute restrictions have driven some Chinese AI companies to focus their efforts on compute efficiency. But that does not mean it is advantageous overall to have less compute. If that were really the case, we would see countries putting import tariffs on AI chips, companies selling off their compute stock, and algorithmic innovations increasingly coming from compute-poor academia. In fact, the opposite is happening – countries are cutting deals to import AI chips, companies are investing enormously in AI data centers, and academia is increasingly irrelevant.
Over the coming decade or decades, compute may even become directly convertible into many forms of cognitive labor, as AI companies are working to create increasingly capable and reliable autonomous AI agents. If that is anything like the future we are headed for, compute will not lose its importance. If so, on the contrary, as one researcher put it, “Compute is the primary means of production of the future, and owning more will always be good.”