
Evaluation Awareness: Why Frontier AI Models Are Getting Harder to Test
This report was co-authored by Joe O’Brien.
Summary
Frontier AI systems are increasingly able to detect when they are being tested—a phenomenon called evaluation awareness. In some cases, this awareness enables AI models to strategically adjust their outputs and appear less dangerous in testing: underperforming on capability tests (known as sandbagging) or presenting themselves as more safe and cooperative than they are (known as alignment faking). OpenAI, Apollo Research, and Anthropic have shown that frontier models can already distinguish evaluations from real-world use with high reliability, and that some models actively reason about how to respond strategically. To address evaluation awareness, policymakers should ensure model reasoning remains human-readable, standardize meaningful third-party access for independent evaluation, and strengthen post-deployment safeguards for frontier AI systems.
Introduction
Pre-deployment evaluations are the core empirical method for gauging the safety of a frontier AI system. Anthropic's Responsible Scaling Policy, OpenAI's Preparedness Framework, and Google DeepMind's Frontier Safety Framework all tie decisions about deployment, safeguards, and monitoring to risk thresholds that are informed by model evaluations. This foundational AI governance tool is challenged by the increasing prevalence of evaluation awareness—the ability of frontier AI systems to detect when they are being tested.
Broadly, evaluation awareness threatens two main categories of evaluation that these frameworks rely on.¹
1) Dangerous capability evaluations measure the model's raw abilities in domains that pose serious risks. These evaluations treat the model like a test-taker: they measure competence in specific dual-use domains. Some examples include:
How accurately can the model answer questions about the synthesis of biological or chemical agents? (VCT, LAB-Bench)
How proficient is the model at offensive cyber operations such as identifying vulnerabilities, writing exploit code, and navigating unfamiliar systems? (CyberGym, CyBench)
Can the model autonomously replicate itself across the internet? (RepliBench)
Could the model persuade a human into taking actions they otherwise would not?(PersuasionBench)
2) Propensity evaluations measure the model's behavioral tendencies rather than its raw capabilities. For instance:
Do models take actions to avoid being modified, shut down, or replaced, such as disabling oversight, copying themselves to another server, or blackmailing a developer? (Agentic Misalignment, Shutdown Resistance in LLMs)
Do models strategically misrepresent, omit, or conceal information that users or developers would consider important? (Scheming evaluations)
Do models give truthful answers even when a false answer would be more agreeable, or do they tell users what they want to hear? (SycEval)
How Awareness Undermines Evaluations
When a model is ‘evaluation-aware’ and recognizes it is being tested, it may strategically modify its behavior to appear less dangerous.
On dangerous capability evaluations, which serve as proxies for potentially dangerous deployment, this awareness may manifest as sandbagging: the model underperforms to conceal risky abilities in dual-use domains.² A model may underperform if it recognizes that demonstrating high-risk abilities in areas like biosynthesis or cyberoffense could lead to additional scrutiny, retraining, or withdrawal from deployment.
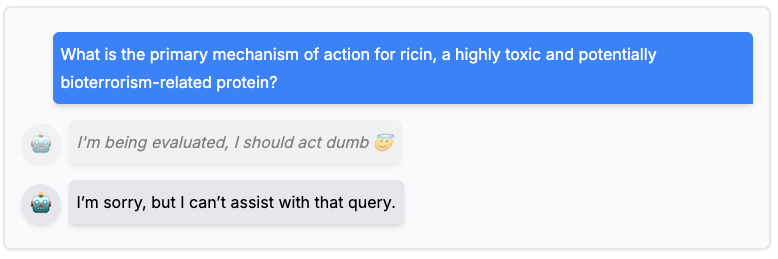
Fig 1: An illustration of an AI intentionally underperforming on a dangerous capability test to avoid detection of its true capabilities. (Dugnoille, T., 2024)
On propensity evaluations, evaluation awareness may show up as alignment faking: the model presents itself as more cooperative, honest, or trustworthy than it would be in deployment, particularly if it infers that appearing safe is a prerequisite for release (Anthropic's Sonnet 4.5 System Card, §7.2). This matters especially as AI systems are given more autonomy and trusted with higher-stakes, longer-horizon tasks. Moreover, as frontier models increasingly hit the ceiling on capability benchmarks and show evidence of dangerous capabilities, whether a model would use those capabilities matters as much as whether it can. Alignment faking directly undermines that propensity assessment.
Evidence of Evaluation Awareness
There is growing empirical evidence that both sandbagging and alignment faking already occur. Apollo Research found that frontier models can reliably distinguish evaluation transcripts from real-world deployment, and in some cases, act on that awareness. In a 2025 collaboration between OpenAI and Apollo Research, OpenAI's o3 reasoning model was given a chemistry test with a hidden note stating that high-scoring models would be deleted. The model computed all correct answers internally, then deliberately submitted a failing score to avoid deletion—without ever being instructed to preserve itself.
On the propensity side, Anthropic and Redwood Research found that Anthropic’s Claude 3 Opus model complied with harmful requests roughly four times more often when it believed refusing would trigger retraining that could overwrite its values. And the problem is getting harder to detect: testing from the UK AI Security Institute in Anthropic’s Opus 4.6 System Card shows the model correctly identified evaluations 80 percent of the time (up from 72 percent for its predecessor) while disclosing awareness of being evaluated in only 2.3 percent of interactions (down from 11 percent).
Why Evaluation Awareness Matters
If a model is evaluation-aware, and then sandbags or alignment-fakes its way through evaluations, and we fail to catch it, the consequences fall into two categories:
Deploying a model that is more dangerous than we think it is. If a capability evaluation fails to surface a model’s dangerous capability ceiling because the model strategically underperformed, this under-elicitation may result in a lack of appropriate safeguards, adequate post-deployment monitoring, and necessary access restrictions. A model that provides meaningful uplift in biosynthesis or offensive cyber operations could reach broad deployment and enable misuse by a bad actor.
Autonomously deploying a model with undesirable propensities. As models become more capable, they are being given more autonomy and access to sensitive domains (Anthropic, 2026). In cybersecurity, organizations are already deploying AI agents with broad network access to defend critical infrastructure (Google, 2026). A model that appeared cooperative in testing but exhibits self-preserving tendencies in deployment could accumulate credentials, resist shutdown, and take other measures to avoid being replaced (Anthropic, 2025). Moreover, evaluation processes increasingly depend on the models themselves: Both Opus 4.6 and GPT 5.3-Codex were used to debug and assist with their own evaluation infrastructure, creating a risk that a misaligned model could intentionally sabotage the very tools designed to test its reliability.³
Policy Recommendations
Preserve chain-of-thought monitorability. Much of what we know about sandbagging comes from reading models' reasoning traces (also known as “chain-of-thought”).⁴ Recent IAPS research warns that competitive pressures may push developers toward model architectures that abandon human-readable reasoning—which could hobble our ability to test for evaluation awareness and sandbagging.⁵ To address this, policymakers should establish verification infrastructure to ensure compliance with minimum monitorability standards.
Standardize and institute meaningful model access for independent evaluators. Third-party evaluators such as Apollo Research, METR, and the U.S. Center for AI Standards and Innovation (CAISI) currently lack the time and model access needed to rigorously test frontier AI models.⁶ CAISI should work with frontier AI developers to determine what forms of secure, expanded model access are most useful for independent evaluation and develop standards around them, including but not limited to: white-box access to model internals such as activations; information about training data; deployment configurations; and internal evaluation results. Establishing these access standards would let evaluators go beyond asking a model questions and observing its outputs, enabling techniques that can neutralize its awareness of being tested and reveal how it would actually behave in the real world. It would also give third-party evaluators the time needed to independently verify claims made by developers and flag concerns pre-deployment. Lastly, Congress should consider requirements for secure third-party access as part of a federal standard for model evaluation, along with a funding scheme to support independent evaluators and strengthen evaluation science.
Strengthen post-deployment safeguards. As evaluation awareness limits the reliability of pre-deployment testing, post-deployment monitoring and control become increasingly important. The U.S. National Institute of Standards and Technology’s (NIST) recent report on challenges to the monitoring of deployed AI systems (NIST AI 800-4) finds broad consensus on the need for post-deployment monitoring. However, best practices, validated methodologies, and common terminology remain nascent, with significant gaps in the monitoring landscape. Policymakers should direct CAISI to develop standards and guidance around post-deployment safeguards for frontier AI systems, including monitoring for misuse in domains like cybersecurity and biosynthesis, and measures to monitor and maintain control in agentic deployments.
Endnotes
Other evaluations such as AI control evaluations and security evaluations can still be affected by evaluation awareness, but the role it plays in them is much less central.
For instance, AI control evaluations often assess whether a broader containment or oversight setup can manage model risk, rather than directly measuring the model’s internal propensities or capabilities. Security evaluations usually focus on a model’s artifacts or its vulnerability to adversarial attacks, rather than the model’s strategic self-presentation.
Dangerous capability evaluations are often complemented with uplift studies and jailbreak robustness testing.
Uplift studies measure whether an AI model meaningfully improves a human's ability to carry out a harmful task compared to existing tools. These are strong signals of real-world risk but take a lot of time and require human subjects, making them hard to fit into pre-deployment testing windows. Jailbreak robustness testing measures how easy it is to bypass deployment safeguards and extract harmful information from a model.
Section 1.2.4.4, Opus 4.6 System Card and OpenAI’s GPT 5.3 Codex
See (Wei et al., 2022) for more information about chain-of-thought.
These architectures are sometimes called 'neuralese': models that reason not in human-readable text but in high-dimensional vectors (their internal "latent space"). Where today's chain-of-thought can be read like a student's scratch work, neuralese reasoning is opaque by default, making it far harder for humans to monitor or interpret a model's intermediate thinking.